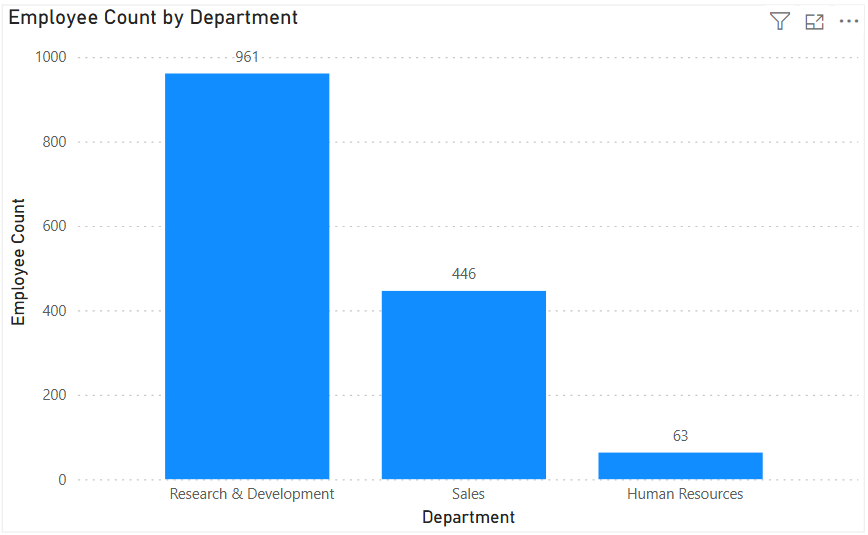
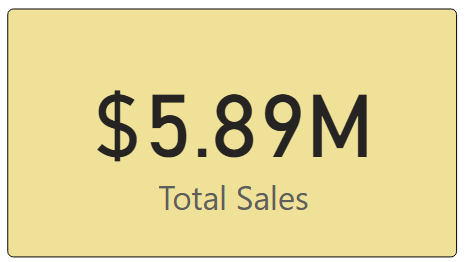
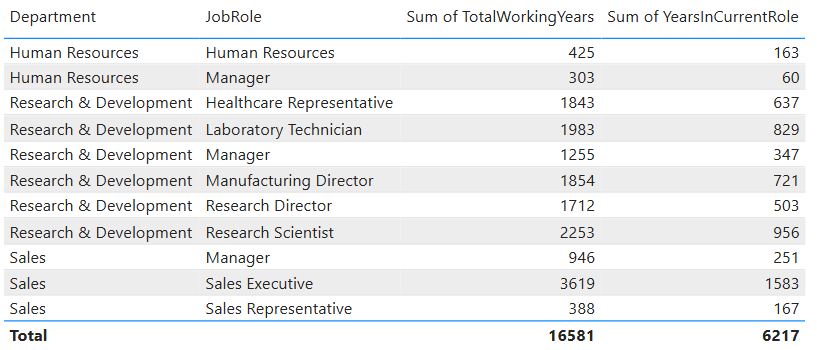
Self-service analytics has become a cornerstone of modern data strategies. As organizations generate more data and business users demand faster insights, relying solely on centralized analytics teams creates bottlenecks. Self-service analytics shifts part of the analytical workload closer to the business—while still requiring strong foundations in data quality, governance, and enablement.
This article is based on a detailed presentation I did at a HIUG conference a few years ago.
What Is Self-Service Analytics?
Self-service analytics refers to the ability for business users—such as analysts, managers, and operational teams—to access, explore, analyze, and visualize data on their own, without requiring constant involvement from IT or centralized data teams.
Instead of submitting requests and waiting days or weeks for reports, users can:
- Explore curated datasets
- Build their own dashboards and reports
- Answer ad-hoc questions in real time
- Make data-driven decisions within their daily workflows
Self-service does not mean unmanaged or uncontrolled analytics. Successful self-service environments combine user autonomy with governed, trusted data and clear usage standards.
Why Implement or Provide Self-Service Analytics?
Organizations adopt self-service analytics to address speed, scalability, and empowerment challenges.
Key Benefits
- Faster Decision-Making
Users can answer questions immediately instead of waiting in a reporting queue. - Reduced Bottlenecks for Data Teams
Central teams spend less time producing basic reports and more time on high-value work such as modeling, optimization, and advanced analytics. - Greater Business Engagement with Data
When users interact directly with data, data literacy improves and analytics becomes part of everyday decision-making. - Scalability
A small analytics team cannot serve hundreds or thousands of users manually. Self-service scales insight generation across the organization. - Better Alignment with Business Context
Business users understand their domain best and can explore data with that context in mind, uncovering insights that might otherwise be missed.
Why Not Implement Self-Service Analytics? (Challenges & Risks)
While powerful, self-service analytics introduces real risks if implemented poorly.
Common Challenges
- Data Inconsistency & Conflicting Metrics
Without shared definitions, different users may calculate the same KPI differently, eroding trust. - “Spreadsheet Chaos” at Scale
Self-service without governance can recreate the same problems seen with uncontrolled Excel usage—just in dashboards. - Overloaded or Misleading Visuals
Users may build reports that look impressive but lead to incorrect conclusions due to poor data modeling or statistical misunderstandings. - Security & Privacy Risks
Improper access controls can expose sensitive or regulated data. - Low Adoption or Misuse
Without training and support, users may feel overwhelmed or misuse tools, resulting in poor outcomes. - Shadow IT
If official self-service tools are too restrictive or confusing, users may turn to unsanctioned tools and data sources.
What an Environment Looks Like Without Self-Service Analytics
In organizations without self-service analytics, patterns tend to repeat:
- Business users submit report requests via tickets or emails
- Long backlogs form for even simple questions
- Analytics teams become report factories
- Insights arrive too late to influence decisions
- Users create their own disconnected spreadsheets and extracts
- Trust in data erodes due to multiple versions of the truth
Decision-making becomes reactive, slow, and often based on partial or outdated information.
How Things Change With Self-Service Analytics
When implemented well, self-service analytics fundamentally changes how an organization works with data.
- Users explore trusted datasets independently
- Analytics teams focus on enablement, modeling, and governance
- Insights are discovered earlier in the decision cycle
- Collaboration improves through shared dashboards and metrics
- Data becomes part of daily conversations, not just monthly reports
The organization shifts from report consumption to insight exploration. Well, that’s the goal.
How to Implement Self-Service Analytics Successfully
Self-service analytics is as much an operating model as it is a technology choice. The list below outlines important aspects that must be considered, decided on, and implemented when planning the implementation of self-service analytics.
1. Data Foundation
- Curated, well-modeled datasets (often star schemas or semantic models)
- Clear metric definitions and business logic
- Certified or “gold” datasets for common use cases
- Data freshness aligned with business needs
A strong semantic layer is critical—users should not have to interpret raw tables.
2. Processes
- Defined workflows for dataset creation and certification
- Clear ownership for data products and metrics
- Feedback loops for users to request improvements or flag issues
- Change management processes for metric updates
3. Security
- Role-based access control (RBAC)
- Row-level and column-level security where needed
- Separation between sensitive and general-purpose datasets
- Audit logging and monitoring of usage
Security must be embedded, not bolted on.
4. Users & Roles
Successful self-service environments recognize different user personas:
- Consumers: View and interact with dashboards
- Explorers: Build their own reports from curated data
- Power Users: Create shared datasets and advanced models
- Data Teams: Govern, enable, and support the ecosystem
Not everyone needs the same level of access or capability.
5. Training & Enablement
- Tool-specific training (e.g., how to build reports correctly)
- Data literacy education (interpreting metrics, avoiding bias)
- Best practices for visualization and storytelling
- Office hours, communities of practice, and internal champions
Training is ongoing—not a one-time event.
6. Documentation
- Metric definitions and business glossaries
- Dataset descriptions and usage guidelines
- Known limitations and caveats
- Examples of certified reports and dashboards
Good documentation builds trust and reduces rework.
7. Data Governance
Self-service requires guardrails, not gates.
Key governance elements include:
- Data ownership and stewardship
- Certification and endorsement processes
- Naming conventions and standards
- Quality checks and validation
- Policies for personal vs shared content
Governance should enable speed while protecting consistency and trust.
8. Technology & Tools
Modern self-service analytics typically includes:
Data Platforms
- Cloud data warehouses or lakehouses
- Centralized semantic models
Data Visualization & BI Tools
- Interactive dashboards and ad-hoc analysis
- Low-code or no-code report creation
- Sharing and collaboration features
Supporting Capabilities
- Metadata management
- Cataloging and discovery
- Usage monitoring and adoption analytics
The key is selecting tools that balance ease of use with enterprise-grade governance.
Conclusion
Self-service analytics is not about giving everyone raw data and hoping for the best. It is about empowering users with trusted, governed, and well-designed data experiences.
Organizations that succeed treat self-service analytics as a partnership between data teams and the business—combining strong foundations, thoughtful governance, and continuous enablement. When done right, self-service analytics accelerates decision-making, scales insight creation, and embeds data into the fabric of everyday work.
Thanks for reading!