If you need to build insert statements for many rows of data for inserting that data into another table or into the same table in a different environment, there is a convenient way to do this in Toad. This is often needed to move data around.
In Toad, execute the appropriate select statement on the source table …
Select * from [my_schema].[my_simple_table];
I used a simple “select *” above, but your SQL statement can be any valid SQL statement that returns the data you want to insert into the other table. You may add specific columns, add filters, joins, and any other valid SQL operation.
Let’s say you want to insert the output into another table in a different schema.
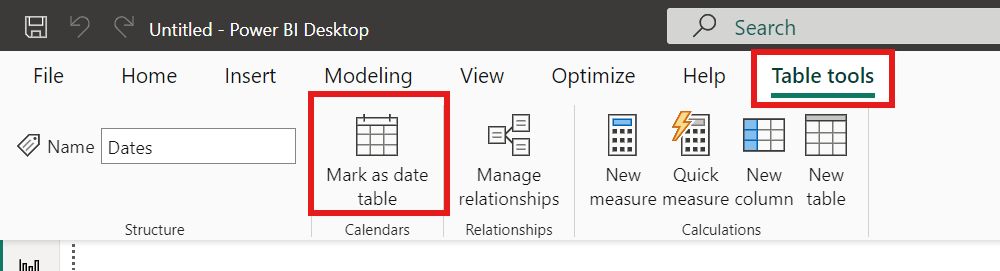
Right-click on the output result data, and click “Export Dataset…”

From the “Export format” drop down menu, choose “Insert Statements”

In the Output section of the Export Dataset dialog box, enter the location and name of the Insert Script file that will be generated.
There are several other parameters that you could choose but we won’t cover them all here.
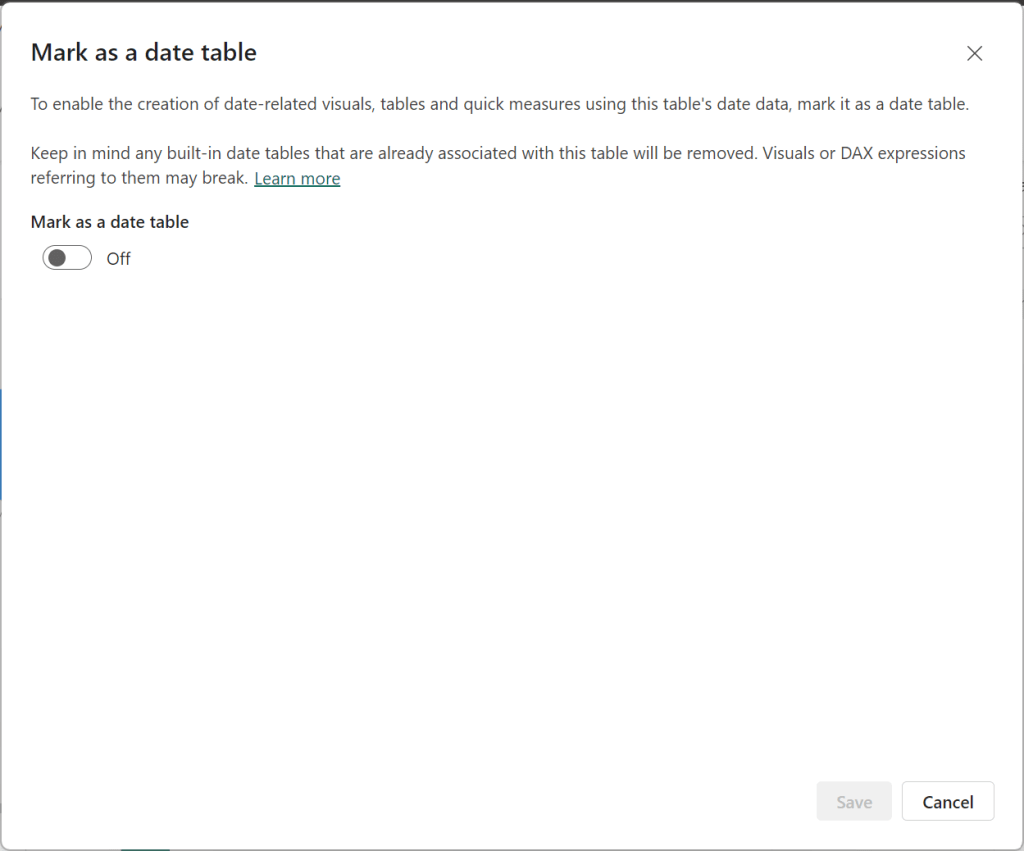
If you only wanted to generate inserts for some selected rows, select “Export only selected rows”.
If you need to specify the schema of the target table, select “Include schema name”
In the Table section, enter the name of the target schema and table
Note, there are data masking options available that can be very useful if, for example, you are moving some data from a Production environment to a Non-Production environment, and you do not want to expose the data there.

After you have set the parameters relevant to your scenario, Click “OK”.
The Insert Script file of all the data will be generated with the filename and at the location you specified. And the insert statements will include the name of the schema and table you specified.

Thanks for reading!